Wide-and-Slow VCSEL Co-Packaged Optics:
A Post-Copper Architecture for AI Scale-Up
March 16, 2026 by Coherent
Source: Jean Teissier; Manuel Kohli. VCSEL-based CPO for Scale-Up in A.I. Datacenter – Status and Perspectives. White paper, Year: 2026
The Post-Copper Reality in AI Datacenters
Artificial intelligence training infrastructure is redefining the requirements of intra-datacenter connections. In modern AI clusters, the scale-up network — the high-bandwidth fabric connecting GPUs within short reach, from racks to pods level — carries the majority of traffic during model training. As model sizes and compute density continue to increase, interconnect performance has become a primary system constraint.
For decades, copper has been the foundation of short-reach communication. However, beyond 200Gbps per lane, scaling speed with copper faces fundamental physical and architectural limitations, including:
- Rising energy consumption driven by high-speed SerDes and Digital Signal Processor (DSP)
- Reduced reach at increasing data rates
- Additional latency from equalization and retiming
- Physical congestion limiting bandwidth density
Driving signals from the processor to the edge of the board already consumes several picojoules per bit and hundreds of nanoseconds latency before transmission even begins. Scaling bandwidth further through copper requires higher SerDes speeds and greater digital signal processing — increasing both power and complexity, while impacting the reach.
AI infrastructure is forced to enter a post-copper era for scale-up networks. This paradigm change requires minimizing the length of copper traces and thus reducing power consumption. The path forward is to bring optical transceivers closer to the processing unit, ultimately co-packaging them together.
Co-Packaged Optics: A Structural Shift
Co-Packaged Optics (CPO) integrates the optical engine directly alongside the processor, reducing the electrical signal propagation losses. By optimizing the whole link, a CPO approach can drastically lower the overall energy consumption and latency by reducing or even removing the electrical DSP. This comes at the cost of more constraints on the optical engine, increasing reliability requirements for elevated temperature while decreasing the allowed footprint.
Yet, the main benefit of moving away from copper is the spatial or wavelength multiplexing in the optical domain. As such, CPO allows the optimization of the whole link on the key metrics: lower energy consumption and faster links with better stability and reliability.
The emerging design question is no longer simply copper or optics?
It is:
Fast-and-Narrow — or Wide-and-Slow?
Fast-and-Narrow vs. Wide-and-Slow Architectures
Current optical implementations extend the traditional copper paradigm: fewer lanes operating at high speeds using PAM4 modulation and advanced DSP. This fast-and-narrow approach maintains compatibility with existing high-speed SerDes architectures and allows for fewer lanes to achieve the required aggregated bandwidth. The cost of this approach is higher signal-to-noise requirements, additional processing stages, and increased energy overhead.
The alternative model emphasizes parallelism over high per-lane speed. In a wide-and-slow (WaS) architecture:
- More optical lanes operate at moderate bitrates
- NRZ signaling can be employed
- DSP requirements are reduced or removed altogether
Lower per-lane speeds relax signal integrity constraints and enable simplified electronics, improved robustness, and lower energy per bit. For AI scale-up networks — where aggregated bandwidth, efficiency, and reliability are critical — wide-and-slow architectures align naturally with system-level optimization. Instead of forcing the time multiplexing, it trades it for other types of multiplexing, like spatial or spectral.
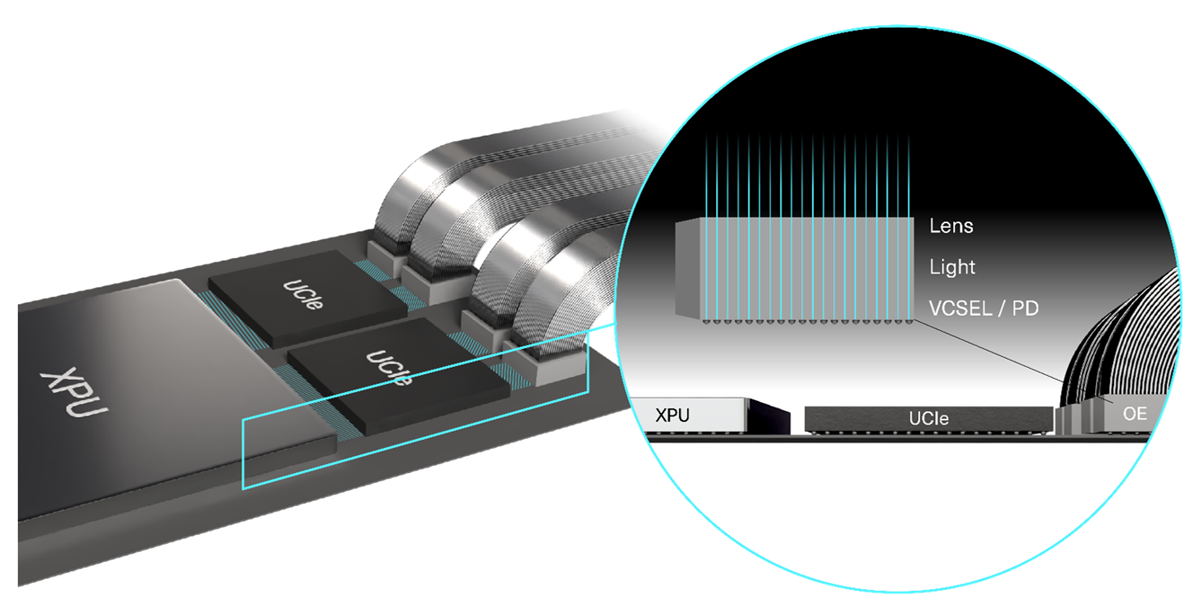
VCSEL CPO: Energy-Efficient Interconnects Across Speeds
Vertical-Cavity Surface-Emitting Lasers (VCSELs) offer a unique combination of efficiency, scalability, and manufacturing maturity. That makes them optimal for CPO applications, regardless of speed-per-lane.
High Efficiency Across Bitrates
VCSELs are well suited for a large variety of speeds, maintaining a strong wall-plug efficiency across a broad operating range. This versatility in addition to the small size provides architectural flexibility without sacrificing energy performance.
Proven Manufacturing and Reliability
VCSEL technology has been deployed in datacom applications for decades, with extensive manufacturing experience and field reliability. Operating at moderate speeds can further reduce electrical and thermal stress, supporting long-term stability.
Direct Modulation and Channel Independence
VCSELs can be deployed in arrays, where each emitter can be driven independently from all the others. Each VCSEL channel is directly modulated and physically independent. This enables:
- Lane-level isolation
- Localized fault containment
- Practical implementation of spare lanes
- Enhanced resilience at cluster scale
Unlike architectures that rely on shared optical paths, physically independent channels help prevent faults from propagating across the system.
Advantages of the Wide-and-Slow Approach
Latency in Large-Scale AI Systems
While energy efficiency receives significant attention, latency is equally important in tightly synchronized AI training systems. High-speed PAM4 links with complex DSP introduce additional processing stages and retiming overhead. Wide-and-slow NRZ architecture reduces signal processing complexity and simplify the electrical chain, helping minimize delay and reducing costs
Reliability and Link Stability
The training phase of a model is sensitive to any interruption. A single interruption of a scale-up link may require a restart of the phase to the last backup point, significantly impacting cost.
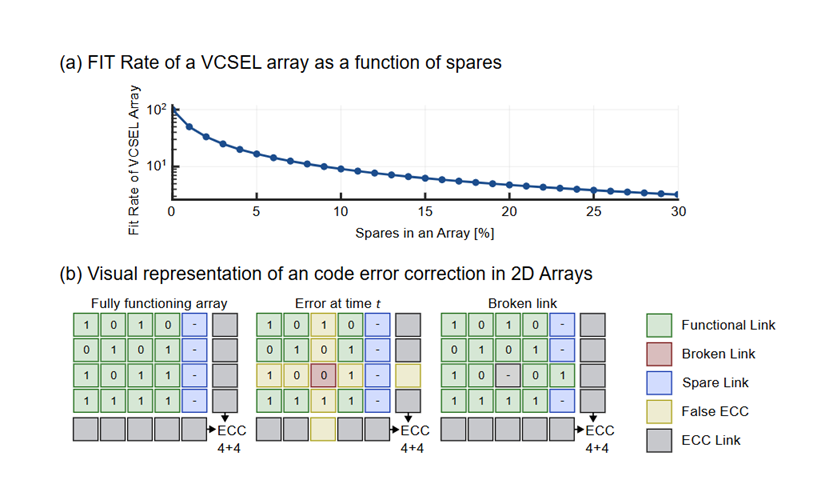
Wide-and-slow VCSEL arrays enhance reliability through:
- Lower powers per-lane and thus lower stress
- Simplified signal processing and less decision points
- Independent optical channels
- Practical spare-lane redundancy
Because each channel operates independently, faults remain localized rather than propagating across shared optical structures. A wide-and-slow approach, spares can be introduced with small overhead. Furthermore, simple Error Code Correction (ECC) can be introduced without noticeable latency or energy overhead.
Bandwidth Density: A Critical Scaling Metric
Beyond energy efficiency, AI interconnect scaling increasingly depends on bandwidth density, typically expressed in Tbit/s per mm².
VCSEL arrays operating at moderate per-lane speeds and fine pitch can deliver multi-terabit-per-square-millimeter bandwidth density without relying on extreme modulation complexity. This provides meaningful headroom for continued AI infrastructure growth.
Energy Efficiency: Approaching Sub-1pJ/bit Performance
Energy efficiency is a defining metric for AI scale-up networks. A balanced wide-and-slow VCSEL CPO architecture — combining simplified electronics, reduced DSP, efficient drivers, and careful electro-optical co-design — has the potential to approach sub-1pJ/bit total link energy, end to end.
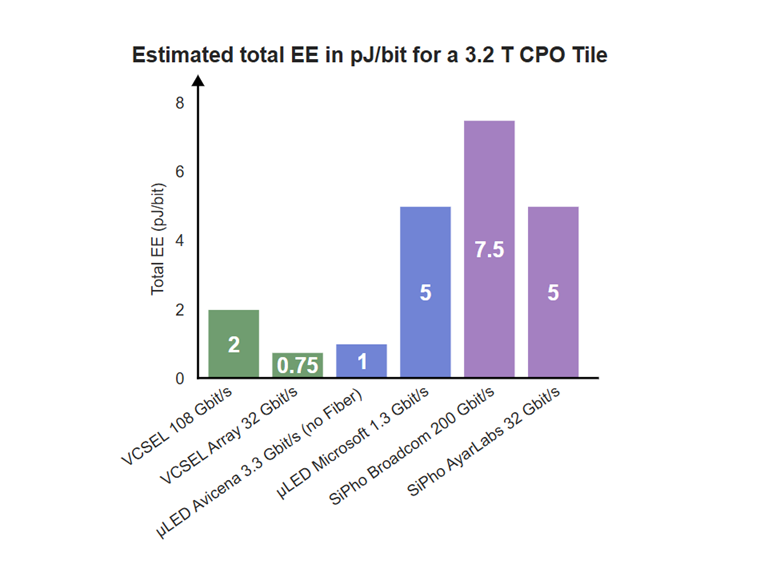
Positioning Among Emerging Optical Approaches
Several technologies are being explored for co-packaged optics in AI datacenters, including microLED emitters and silicon photonics solutions.
Each approach offers distinct advantages. VCSEL-based wide-and-slow CPO provides a balanced combination of:
- High wall-plug efficiency
- Directly modulated emitters
- Energy efficiency at wide range of speeds
- Fiber compatibility
- Channel-level independence
- Established manufacturing maturity
This balance positions wide-and-slow VCSEL architectures as a compelling and scalable option for AI scale-up networks.
Conclusion: Toward Photonics-First AI Infrastructure
The transition from copper to optics in AI scale-up networks is well underway. The next architectural evolution may be the shift from fast-and-narrow designs toward wide-and-slow, highly parallel optical fabrics optimized for efficiency, latency, and resilience.
Wide-and-slow VCSEL co-packaged optics represents a practical pathway toward photonics-first AI infrastructure — enabling the performance, energy efficiency, and reliability required for next-generation AI datacenters. It leverages on a mature ecosystem with proven cost model and reliability at scale. Rather than incremental improvement, this represents an architectural shift driven by parallelization and simplification. As copper approaches its fundamental performance limits, optics should no longer be treated as a direct extension of a copper interconnect; instead, the system architecture should be fully optimized by taking advantage of multiplexing in the optical domain.



